Business Implications
Understanding token patterns and burst behavior is essential before scaling LLM applications in production. This simulator provides early visibility into load fluctuations, allowing teams to model cost, latency, and GPU requirements more accurately. It reduces guesswork in capacity planning, enabling more reliable, cost-efficient LLM deployment strategies and forming the foundation for intelligent autoscaling research.
Steps Performed
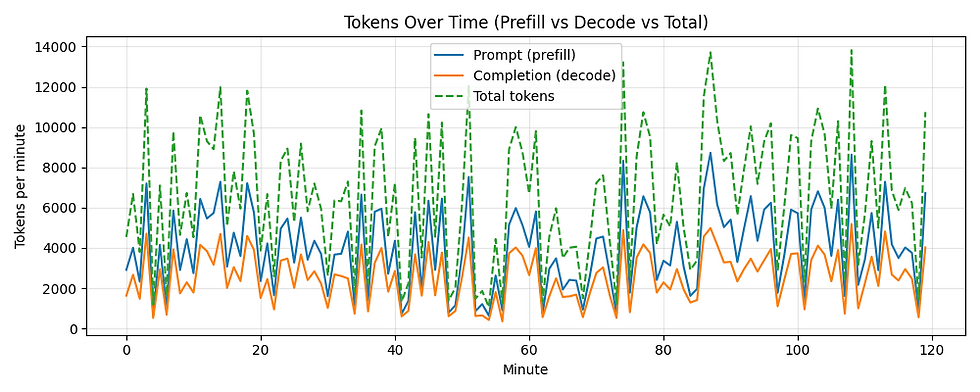
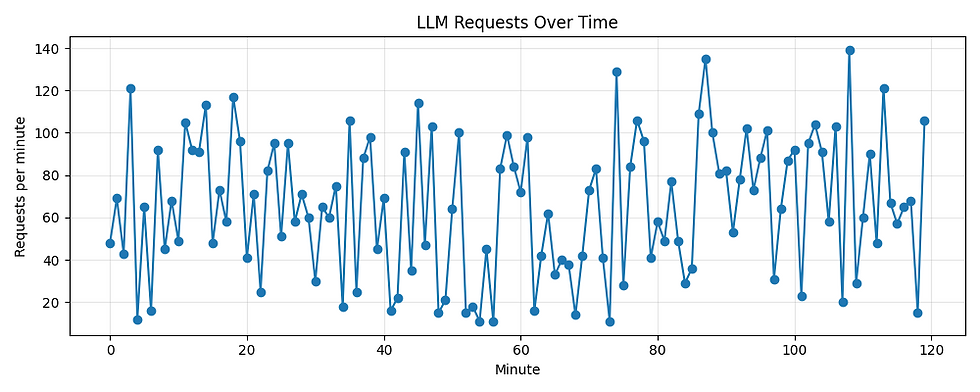
Designed a synthetic traffic model for LLM requests, generated time-series token workloads, and visualized bursts, prefills, and decodes. Exported structured CSV traces to feed into baseline and RL autoscaling experiments for cost/latency research
1.
Designed LLM Workload Framework
Defined a synthetic inference workload structure including arrival rate, burstiness, and log-normal prompt/completion token distributions.
2.
Implemented Request Generation Engine
Used Poisson processes to simulate real-world LLM request bursts with configurable parameters for traffic intensity and variance.
3.
Modeled Token Behavior
Generated prompt vs decode token lengths using log-normal sampling to reflect realistic LLM input/output patterns.
4.
Aggregated Minute-Level Metrics
Converted raw request traces into per-minute summaries for tokens, request counts, and prefill/decode breakdowns.
5.
Produced Analytical Visualizations
Generated plots for request patterns, token dynamics, and token-length distributions—exported automatically into a structured /plots directory.
AWS Services Used
None
Python
NumPy
Pandas
Matplotlib
Technical Tools Used
Workload Simulation
Data Visualization
Statistical Modeling
ML Systems Analysis
Skills Demonstrated

LLM Load Simulator & Token Pattern Visualizer
Synthetic LLM workload generation to analyze request bursts and token behavior.
A lightweight simulator that produces synthetic LLM inference traffic which including bursts, prompt/decode token patterns, and minute-level workload traces which is used to understand how LLM workloads behave under load before designing auto-scaling strategies.





